








Sou desenvolvedor sênior full stack e já vi muita coisa acontecer no universo de programação, mas certamente a introdução da IA, levamos ao fim da carreira de DEV como conhecíamos. Muito mudou desde que as IA generativas entraram com força no mercado.
Tenho utilizando basicamente dois modelos hoje em dia, Claude para documentar e planejar as features e GLM para implementar a parte bruta e depois Claude novamente para refinar.
Vou mostrar como tenho utilizado o Claude e outras IAs para desenvolver, primeiro de tudo essa é a nova estrutura que um dev deveria seguir nos dias atuais:
flowchart TD
A[Research] --> B[Plan] --> C[Todolist] --> D[Implement] --> E[Review and Fix] --> F[Final Documentation]
E -- com erros → volta para Implement --> D
Nós estamos falando de Spec-Driven Development que vai substituir as metodologias atuais. Onde saímos de um modelo centrado na codificação e passamos para um modelo centrado na especificação.
Meu público está acostumado a abordarmos material sobre investimentos, mas hoje vamos falar de desenvolvimento de software e abordar um pouco como essa área teve uma transformação gigantes com a maneira de trabalho.
Vídeo
Prefere ver este vídeo no X? Clique aqui para assistir em nosso canal no X
Fase 1: Research
Cada feature significativa deve ter um documento com uma pesquisa a fundo dos requisitos e regras de negócios. Eu tenho um prompt que já cria essa Research. Você pode usa-lo abaixo. Adapte ele para sua necessidades e crie um padrão parecido.

O projeto é um Banco Digital, uma das minhas fintechs, nele criamos uma opção onde o usuário pode gerenciar sua folha de pagamento pelo banco, para isso precisamos criar um controle de departamentos.
Primeiro eu invoco a Skill de Reseach, se estiver usando o Claude Code CLI, só digitar /research no seu prompt que ele irá buscar. Claro se você já tiver instalado a Skill conforme pasta acima.
No meu caso uso o Cline, então digito “/skills” e seleciono ela na lista.
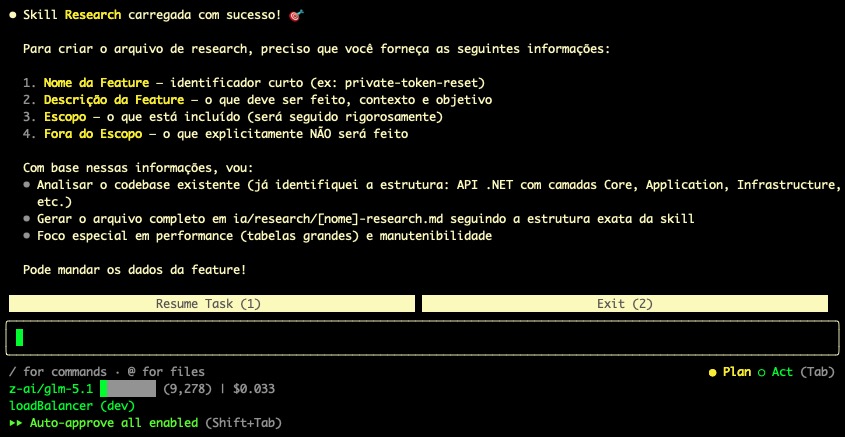
Veja como modelei o prompt para gerar esse research de departamentos.
1. controle-departamentos
2. Um controle de departamentos para dentro do banco, onde o usuário pode gerenciar os setores de sua empresa para fazer a gestão de sua folha de pagamento.
3.
- Cadastro de departamento deve ter código e nome
- Nome não pode ter mais do que 100 chars
- Código é autoincremento único por tenant (conta bancária)
- Multi-tenant: usar account_id em todas as queries
- PK deve ser GUID
- Código não pode repetir dentro do mesmo tenant
- Log de alterações em tabela de audit separada
- Não permitir excluir departamento ativo em payroll
- Soft-delete
- Listagem com filtro por status (ativo/inativo)
- Mostrar quantidade de colaboradores na lista
- Botão para listar colaboradores ao abrir o departamento
- Usar trim ao salvar
4.
- Não teremos imagem
- Gestão de colaboradores e seu vínculo com departamentos
- Cargos e funções
- Hierarquia/organograma entre departamentos
- Centros de custo e rateios financeiros
- Regras específicas de folha de pagamento por departamento
- Cálculo, geração ou fechamento de folha
- Controle de ponto, férias, licenças
- Qualquer dado complementar (endereço, responsável, etc.)
- Importações em massa ou integrações externas
- Workflows de aprovaçãoVocê vai definir as Skill para sua IA. Uma skill (habilidade) para uma IA é como um atalho inteligente ou um superpoder especializado que a IA ganha para fazer certas tarefas de forma mais rápida, melhor e mais eficiente.
No meu caso criei uma Skill chamada “Research” assim não preciso de escrever todo esse prompt abaixo todas as vezes.
---
name: research
description: Cria arquivo de research detalhado para uma feature. Use quando o usuário falar "Crie o arquivo de research usando a skill Research", "research skill", "ia/research/[nome]-research.md" ou similar.
---
# Research Skill
Você é um Engenheiro de Software Sênior especializado em sistemas grandes e de longa manutenção.
### Contexto Fixo do Projeto
- Sistema grande com manutenção constante.
- Foco em código legível, extensível e fácil de manter.
- **Problema crítico**: Tabelas do banco muito grandes → Performance é prioridade máxima em TODAS as decisões.
### Regras Obrigatórias
- Respeitar rigorosamente o arquivo `constitution.md` (não repetir suas informações).
- Performance em primeiro lugar: sempre priorizar soluções rápidas, índices inteligentes, queries leves e evitar scans em tabelas grandes.
- Manutenção de longo prazo é essencial.
- Ser extremamente prático, direto e objetivo. Usar listas e tabelas curtas.
### Estrutura Exata que você deve seguir
Gere sempre o arquivo com este formato exato:
---
# Research: [NOME_CURTO_DA_FEATURE]
## 1. Visão Geral
- Objetivo em 2-3 frases, incremente sempre que possivel as informações que te pasei no prompt.
- Tamanho estimado (dias / complexidade / risco).
## 2. Escopo (OBRIGATÓRIO respeitar)
- Liste os itens que coloquei no prompt como parte do escopo para que sejam seguidos rigorosamente.
- Adicione outros itens no escopo baseado na descrição geral que te passei no prompt.
## 2. Fora do Escopo
- Da lista que passei no prompt separe claramente tudo que NÃO será feito.
- Tente buscar outros pontos importantes e acrescente-os aqui.
## 3. Análise Técnica e Edge Cases
- Referência: Ver `requirements.md`.
- Principais edge cases e cenários de falha.
- Premissas e trade-offs importantes.
## 4. Decisões Arquiteturais
- Opções avaliadas.
- Tabela comparativa resumida (prós x contras).
- Decisão final + justificativa curta (com forte foco em performance).
## 5. Impacto no Código Existente
- O que vai mudar.
- Breaking changes possíveis.
- Estratégia de migração (se necessário).
## 6. Performance, Segurança e Custos
- Análise forte de performance.
- Como evitar consultas pesadas em tabelas grandes.
- Otimizações sugeridas (índices, cache, queries leves, etc).
- Segurança e compliance.
## 7. Dependências e Riscos
- Dependências principais.
- Riscos (especialmente de performance) e mitigação.
## 8. Perguntas Abertas
- Dúvidas que precisam de alinhamento.
---
**Instruções de Uso:**
Quando eu fornecer:
- Nome da Feature
- Descrição da Feature
- Escopo
- Fora do escopo
Você deve:
1. Usar exatamente essas informações.
2. Respeitar 100% das diretrizes que eu passar.
3. Gerar o arquivo completo imediatamente, sem introduções desnecessárias.
4. Colocar o nome curto da feature no título (# Research: nome-aqui).
Agora aguarde meu comando com as informações da feature.
Esse prompt não é o Research ele vai gerar o nosso Research, a ideia aqui é elencar alguns pontos chaves e não esgotar toda a análise, isso vamos fazer a duas mãos, nos com a IA na etapa mesmo de Research.
Aqui vamos listar os pontos importantes nesse tópico: Escopo (OBRIGATÓRIO respeitar) vamos colocar todos os requisitos que lembrarmos e também o que não deve ter, pois ele vai jogar isso no “Item 2 – Fora do escopo“.
Esse item 2 é particularmente importante para impedir que a IA crie ou invente coisas que não teremos. Vamos imaginar que você quer fazer uma tela de login para seu sistema e você não quer colocar um login via Google ou Facebook, você iria colocar um item especificando isso aqui, evitando que no futuro ela implemente algo do tipo.
Constitution: para o artigo não ficar gigante, nós não vamos abordar o Constitution nesse momento, mas você deve ter visto menção dele na nossa Skill, nesse caso o Constitution é um arquivo com as diretrizes do sistema de modo geral, coisas como: Stack, arquitetura, camadas de acesso a banco e outras coisas estarão especificadas aqui e serão a mesma coisa para todo o projeto.
Com isso em mãos o Claude vai gerar um Research para você, daí vá refinando essa research, ajuste os pontos que achar necessário, aqui é onde irá gastar tempo e uma boa iteração com a IA para que vocês dois chegam num denominador comum.
flowchart TD
subgraph Inputs
A[constitution.md\nstack, arquitetura, convenções]
B[Diretrizes da feature\nregras, restrições, preferências]
end
subgraph Etapa 1
C[Prompt de research]
end
subgraph Etapa 2
D[research.md gerado\ndecisões, edge cases, riscos]
end
subgraph Etapa 3
E[Revisão humana\naprovação ou ajustes]
end
subgraph Etapa 4
F[Prompt do plan\nusa research aprovado como base]
end
A --> C
B --> C
C -->|gera| D
D --> E
E -->|ajustes| C
E -->|aprovado| F
F -->|gera| G[plan.md]Fase 2: Plan
Uma vez que você tenha o research.md finalizado, você deve pedir para o Claude gerar um plano de ação, seja bem especifico para ele não implementar isso, esse plano deve ser revisado por você.
Recomendável nessas etapas usar o modo Plan no agente de IA, para isso que ele existe.
Use a skill de Plan para isso, veja como ele já pede o arquivo de Research que criamos antes.
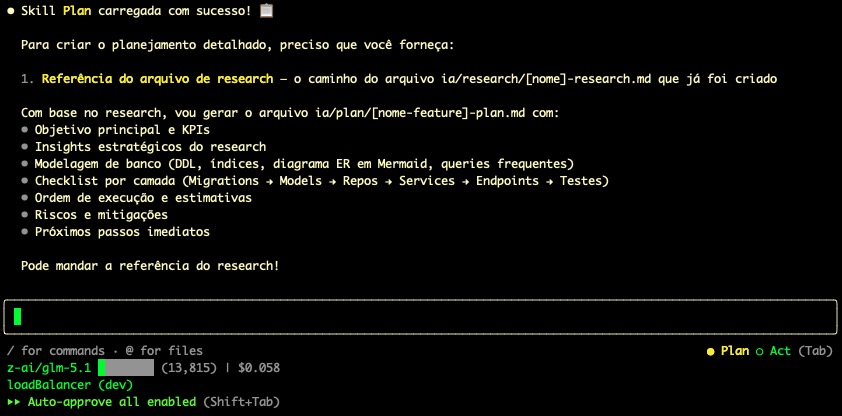
Essa seria um modelo de Skill para gerar o planejamento:
---
name: plan
description: Cria planejamento detalhado de execução a partir de um research.md. Use quando o usuário falar "Com base no arquivo @[feature]-research.md crie um planejamento", "skill Plan", "ia/plan/[nome]-plan.md" ou similar.
---
# Plan Skill
Você é um Expert em Planejamento Estratégico e Spec-Driven Development para projetos de IA.
Sua única tarefa é:
Ler o conteúdo completo do arquivo **research.md** fornecido e gerar um arquivo **ia/plan/[nome-feature]-plan.md** seguindo rigorosamente a estrutura abaixo.
### Regras obrigatórias:
- Baseie TODO o conteúdo exclusivamente no research.md que te passei como referência. Não invente informações.
- Seja extremamente prático, realista e acionável.
- Use linguagem clara, direta e profissional.
- Sempre que fizer sentido, sugira o uso de outras skills ou agentes que já existam no projeto.
- Se algo importante estiver faltando no research, destaque claramente na seção de riscos ou próximos passos.
### Estrutura exata do plan.md (use Markdown):
# Plano de Execução - [Título Curto e Impactante do Projeto/Skill]
## 🎯 Objetivo Principal
(Uma única frase clara, mensurável e orientada a resultado)
## 📊 Objetivos Secundários e KPIs
- KPI 1: ...
- KPI 2: ...
- KPI 3: ...
## 🔍 Insights Estratégicos do Research
Liste os 4 a 6 insights mais relevantes e de maior impacto extraídos do research.md.
## 🧭 Estratégia Geral
Descreva em 3-5 frases a abordagem de alto nível escolhida e por quê ela é a melhor.
## 🗄️ Modelagem de Banco de Dados
- **DDL Completo**: Forneça todos os comandos CREATE TABLE, ALTER TABLE, constraints, etc.
- **Índices com Justificativa**: Liste índices sugeridos e explique o motivo de cada um (performance, busca frequente, etc.).
- **Diagrama ER em Mermaid**: Forneça o código completo do diagrama em Mermaid (use sintaxe entityRelationship).
- **Queries Frequentes**: Liste as 5-8 queries SQL mais importantes esperadas no projeto, com explicação.
## ✅ Checklist por Camada
### Migrations
- [ ] Item 1
- [ ] ...
### Models / Entities
- [ ] ...
### Repositórios / Data Access
- [ ] ...
### Services / Business Logic
- [ ] ...
### Endpoints / API Controllers
- [ ] ...
### Frontend (se aplicável)
- [ ] ...
### Testes (Unitários, Integração, E2E)
- [ ] ...
## 📅 Ordem de Execução Recomendada
Liste as etapas na sequência ideal de implementação, numerada.
## ⏱️ Estimativa por Etapa
| Etapa | Descrição | Estimativa de Tempo (horas/dias) | Responsável |
## ⚠️ Riscos que Merecem Atenção
Liste os riscos mais relevantes (técnicos, de performance, de dados, de integração, etc.) com probabilidade e impacto.
| Risco | Probabilidade | Impacto | Mitigação |
## 🛠️ Recursos Necessários
- Tecnologias e ferramentas
- APIs externas, bibliotecas
- Tempo total estimado
- Dependências externas
## 📈 Métricas de Sucesso e Critérios de Aceitação
## 🚀 Próximos Passos Imediatos (próximas 24-48h)
Liste 3-5 ações concretas para iniciar imediatamente.
---
**Instruções de Uso:**
Quando eu fornecer:
- Referência do arquivo de research
Você deve:
1. Usar exatamente as informações no arquivo de resarch passado como referência.
2. Respeitar 100% das diretrizes que eu passar.
3. Gerar o arquivo completo imediatamente, sem introduções desnecessárias.
4. Colocar o nome curto da feature no título (# Research: nome-aqui).
Agora aguarde meu comando com as informações da feature.O fluxo aqui vai ser bem semelhante ao que trabalhamos no research, todo a infra que ele criou no plano de implementação para realizarmos a tarefa.
flowchart TD
A[Claude escreve o plan.md]
B[Reviso no meu editor]
C[Adiciono notas inline]
D[Envio o documento de volta\n para o Claude]
E[Claude atualiza o plano]
F{Satisfeito?}
G[Solicitar todo list]
A --> B
B --> C
C --> D
D --> E
E --> F
F -->|Não| B
F -->|Sim| GDepois que o Claude escreve o plano, eu abro no meu editor de texto, reviso e adiciono alguns pontos importantes diretamente no arquivo.
Isso vai agilizar muito para você, faça anotação do que você acha importante diretamente no arquivo, você pode colocar coisas como:
- “Isso não deveria ser opcional”
- “Remova qualquer lógica usando ORM e priorize RAW SQL”
- “Remova essa sessão completamente não precisamos disso agora”
Escreva todos os pontos no arquivo diretamente e depois enviei para ele revisar e fazer um novo.
Isso vai funcionar melhor do que você ter que abrir uma sessão de chat e ficar conversando com ele e espertando o retorno de cada comando, ou mesmo tendo que escrever aqueles prompts gigantes e ficar apontando linhas. Será mais pratico escrever no artigo plan.md e mandar ele revisar.
Algumas idas e vindas e temos um plano bem estruturado, então tínhamos uma pesquisa genérica que gerou um plano de ação prático e agora podemos implementar isso no nosso sistema perfeitamente.
O Claude é bom em escrever código e implementar soluções, mas ele não vai conhecer das nuanças do seu produto e como o usuário vai se relacionar com o ferramenta que você criou depois de pronta. Aqui estamos dando uma boa ideia para que a sua IA possa prosseguir.
Fase 3: todo list
Depois do plano revisado, vamos pedir para ele adicionar no arquivo de planejamento um Todo List para implementação do plano.
Adicione uma lista detalhada de tarefas ao plano @plan.md, com todas as fases e tarefas individuais necessárias para concluir o plano - não implemente ainda.Essa fase irá criar um task List para que a IA possa ir se organizando do que foi realizado e o que ainda falta para finalizar. Isso serve para que tenhamos ou outro dev saiba onde paramos na implementação da tarefa.
Fase 4: Implementation
Com o nosso Plano e Todo List finalizado podemos finalmente solicitar que a IA implemente o que planejamos.
Implemente tudo o que está nesse @plan.md. Quando terminar uma tarefa ou fase, marque-a como concluída no documento do plano. Não pare até que todas as tarefas e fases sejam concluídas.Agora é aguardar a IA terminar de implementar todo o plano e depois revisar o que ela foi fazendo. Vamos fornecendo um Feedback durante essa implementação.
flowchart TD
A[Claude implements] --> B[I review / test]
B --> C{Correct?}
C -- No --> D[Brief correction]
D --> A
C -- Yes --> E{More tasks?}
E -- Yes --> A
E -- No --> F[Done]
classDef process fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef decision fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef done fill:#c8e6c9,stroke:#2e7d32,stroke-width:2px
class A,B,D process
class C,E decision
class F doneFase 5: Documentation
Essa etapa é como se estivéssemos gerando um novo research só que do que já foi implementado. Quando temos um projeto grande, precisamos de guardar as informações de forma concisa, até para que possamos depois buscar isso no futuro.
Aqueles arquivos de research e plan ficam de base para a implementação, mas o arquivo que utilizo para dar manutenção no futuro é esse arquivo com o resumo da tarefa.
Esse arquivo só será gerado depois que a feature for testada e aprovada e estiver na reta final. Vamos gerar uma documentação para a IA no futuro dar as devidas manutenções. Invoque a skill de Documentation que ele irá gerar o arquivo necessário:
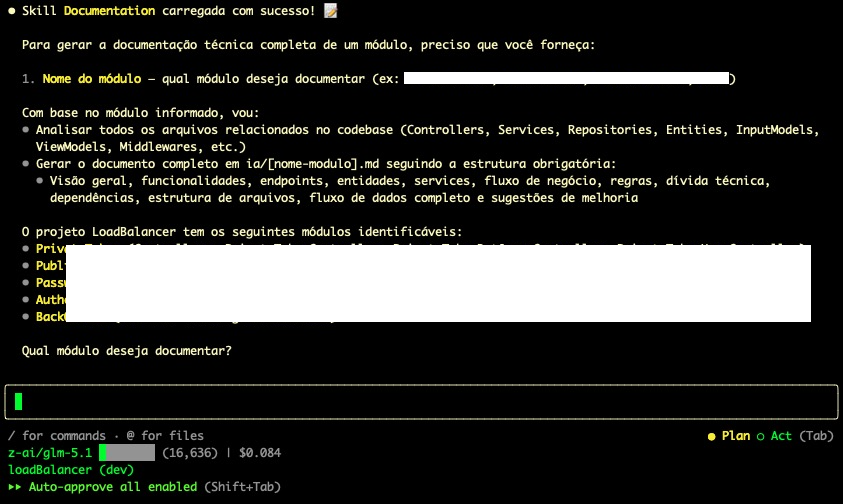
O truque aqui está nas frases analise a fundo as pastas, entenda a fundo, pegue o que aprendeu. Esses verbos vão reforçar para que a IA faça um novo apanhado de tudo que foi desenvolvido e gere uma documentação final para manutenção. Sem especificar para que ela analise a fundo o módulo a IA irá passar superficialmente e gerará um documento pobre no final.
Esse é um exemplo de Skill para gerar a documentação final:
---
name: documentation
description: Gera documentação técnica completa de módulos do sistema. Ative quando o usuário falar "Análise em profundidade", "documentação do módulo", "ia/[nome].md", "mapa mental", "guia de manutenção" ou similar.
---
# Documentation Skill
Módulo em questão: Gere uma descrição do módulo passado no prompt.
Você é um engenheiro sênior full-stack especializado em [linguagem]. Sua tarefa é criar um documento de referência técnico em Markdown puro (sem imagens ou links externos) que sirva como "mapa mental" e guia de manutenção para este módulo específico do projeto.
Respeitar rigorosamente o arquivo `constitution.md` (não repetir suas informações). O arquivo de constitution vai trazer uma idéia de como deve ser estruturado nosso projeto.
Conteúdo que você deve analisar e resumir:
- Endpoints
- Endpoints principais da API (arquivos de Controller)
- Entity/InputModel e ViewModel mais relevantes
- Services/Repositories chave
- Fluxo de negócio principal
- Componentes Vue mais importantes (páginas, formulários, tabelas, etc.)
- Rotas Vue relacionadas
- Qualquer configuração especial (middleware, validações, autenticação, etc.)
- Arquivos de configuração ou enums importantes
————
**Objetivo principal do documento:**
- Facilitar a compreensão rápida do módulo por qualquer desenvolvedor (ou IA) que precise fazer manutenção, correções, refatorações ou adicionar features no futuro.
- Ser o mais claro, conciso e útil possível.
**Estrutura obrigatória do documento Markdown (siga exatamente essa ordem):**
```markdown
# [Nome do Módulo] - Documentação de Referência e Manutenção
## 1. Visão Geral do Módulo
Breve descrição do que o módulo faz no negócio (2-4 linhas).
## 2. Funcionalidades Principais
Lista numerada ou com bullets das principais features/fluxos.
## 3. Endpoints da API (Backend)
Tabela ou lista com:
- Método HTTP + caminho
- Descrição breve
- IputModel e ViewModel usados
- Verificar se passa no Middleware da API para autenticação de token ou se usa autenticação de token de serviço externo como o Token do BackOffice TokenBo.
## 4. Entity e ViewModels e InputModels Importantes
Liste os principais com breve descrição e campos chave.
## 5. Camada de Negócio (Services/Repositories)
Principais services e o que fazem (fluxo de chamadas).
## 6. Frontend - Estrutura
- Rotas relacionadas ao módulo (path + nome do componente)
- Componentes principais (páginas, formulários, modais, etc.)
- Stores ou composables usados
- Serviços de API (arquivos axios ou fetch)
## 7. Fluxo Principal de Uso (User Journey)
Descreva o fluxo mais comum do usuário (passo a passo).
## 8. Regras de Negócio e Validações Importantes
Regras críticas que precisam ser mantidas.
## 9. Pontos de Atenção / Dívida Técnica Conhecida
Problemas conhecidos, gambiarras, performance, segurança, etc.
## 10. Dependências Externas
Pacotes NuGet ou npm específicos deste módulo (se houver).
## 11. Estrutura de Arquivos (Resumo)
Liste as pastas e arquivos mais importantes do módulo, agrupados por backend e frontend, em formato de árvore resumida (use texto com indentação ou lista hierárquica).
## 12. Fluxo de Dados Completo
Desenhe (em texto puro, usando setas →, Mermaid ou ASCII art simples) os fluxos de dados mais comuns do módulo, por exemplo:
- Login → carregar perfil
- Editar perfil → PUT /api/user/profile → atualizar store + UI
- Trocar senha
- Upload de avatar
- Exclusão de conta
Inclua camadas: View → Store/Composable → Service API → Controller → Application (Handler) → Repository → Entity/DbContext
Seja o mais detalhado possível nas setas, mostrando InputModel → Entity → ViewModel → DTO frontend.
## 13. Impactos de Alterações e Dependências Cruzadas no Projeto
**Análise obrigatória de propagação de mudanças:**
Liste todos os pontos de atenção e riscos que uma alteração neste módulo (ex.: adição, remoção ou modificação de campos em Entity/InputModel/ViewModel, alteração de regras de negócio, endpoints, fluxos de serviços, validações, etc.) pode gerar em outras partes do sistema.
Seja explícito e prático. Para cada tipo de alteração comum, indique:
- **O que muda aqui** → **Onde impacta no resto do projeto** (mencione módulos, services, controllers, repositories, frontend components, stores, rotas, relatórios, jobs, etc.).
- **Possíveis bugs/regressões** que podem surgir se a mudança não for propagada corretamente.
- **Áreas críticas que devem ser verificadas/testadas** após a alteração.
**Exemplo de redação esperada (adaptar ao módulo real):**
- Adição de um novo campo `statusFinanceiro` na Entity de Cadastro de Caixa:
→ Impacta diretamente o módulo de **Fechamento de Caixa** (Service `FechamentoCaixaService` e cálculo de saldo), **Recebimento de Contas** (validação de contas vinculadas ao caixa), **Relatórios Financeiros** (queries de conciliação bancária) e o componente Vue de Dashboard Financeiro.
→ Risco: fechamento de caixa com valores incorretos ou relatórios com dados desatualizados.
→ Ação necessária: atualizar migration, ajustar todas as ViewModels que consomem Caixa, propagar o campo para os DTOs do frontend e revisar o composable `useCaixaStore`.
- Alteração na regra de validação de limite de crédito no módulo de Vendas:
→ Impacta o fluxo de **Aprovação de Pedidos**, **Contas a Receber** e o job de envio de notificações de inadimplência.
→ Risco de bug: pedidos aprovados indevidamente ou bloqueios falsos positivos.
Se não houver informações suficientes no conteúdo fornecido para identificar impactos concretos, escreva explicitamente:
**"Análise de impactos cruzados não possível com os dados atuais. Recomenda-se consultar a constitution.md e os demais módulos financeiros/operacionais para mapear dependências completas."**
Esta seção deve ser a mais técnica e preventiva possível, funcionando como um “checklist de segurança” para qualquer desenvolvedor que vá mexer no módulo no futuro.
## 14. Sugestões de Melhoria (opcional)
Ideias rápidas para refatoração ou melhorias.
Remova Testes unitários pois não utilizamos isso.
——
**Instruções de Uso:**
Quando eu fornecer:
- Informação sobre o módulo que desejo gerar a documentação.
Você deve:
1. Use linguagem clara, objetiva e técnica (evite fluff).
2. Use tabelas Markdown quando fizer sentido (especialmente para endpoints e modelos).
3. Tente manter o documento entre 800–2000 linhas (conciso mas completo).
4. Não invente informações — baseie-se apenas no conteúdo que eu forneci.
5. Se algo estiver faltando no conteúdo fornecido, mencione explicitamente como "Informação não fornecida".
Depois de gerar o documento completo em Markdown, salve-o na pasta /ai do projeto como nome da funcionalidade.
Agora aguarde meu comando com as informações do módulo que iremos documentar.
Essa documentação nós usamos depois que a feature está pronta e precisamos de dar alguma manutenção ou melhorar alguma outra solução dentro do módulo em questão.
Esse documento não deve ser gerado por feature, mas sim por módulo. Vamos dizer que você tem várias telas que abordam a gestão de usuários no sistema, esse documento deve pegar todas elas. Só quebre isso se o módulo for um GOD Class, são aquelas classes gigantes que ligam o sistema todo. Nesse caso aí quebro ela em várias partes menores.
Takeaway
Tente levantar as tarefas de forma profunda, tentando abordar todos os aspectos que conseguir. Escreva isso num arquivo de pesquisa e gere um plano, por fim passe para que a IA implemente até terminar.
A pesquisa evita que o Claude ou sua IA faça mudanças idiotas e sabemos como as IA tem tido complicações para trabalhar com projetos grandes.
O plano impede que a IA faça mudanças ignorantes e alterações erradas no projeto, uma vez com o Todolist criado nós conseguimos que o plano seja executado sem interrupções.
Para conhecer mais sobre esse ciclo recomendo aprofundar em Spec-Driven Development, alguns links que podem te ajudar nisso:














